Jaana DoganHow to peacefully grow your serviceIn the last almost two decades, I have seen numerous Internet services ranging from small services for niche markets to Tier 1 services for…Aug 24, 20222Aug 24, 20222
Jaana DoganThree Ways to Trace End-to-endHaving end-to-end distributed traces is a huge challenge for any project. In distributed tracing, end-to-end tracing is a term often used…Jul 7, 20211Jul 7, 20211
Jaana DoganWhy is metric collection still a hard problem in 2020?Metric collection keeps being one of the hard problems. We’ve been collecting metrics for a very long time, so why is this a hard problem…Dec 6, 20202Dec 6, 20202
Jaana DoganWhat did I forget by working for the same company?My Saturday morning coffee is disrupted by this tweet:Nov 22, 20202Nov 22, 20202
Jaana DoganCorrelation in Latency AnalysisThis article was my response to Amazon’s writing assessment when I was interviewed. I answered the question of “What is the most inventive…Oct 22, 2020Oct 22, 2020
Jaana DoganinGoogle Cloud - CommunitySpanner’s SQL StorySpanner is a distributed database Google initiated a while ago to build a highly available and highly consistent database for its own…Jul 22, 2020Jul 22, 2020
Jaana DoganinGoogle Cloud - CommunityHow does Spanner avoid single point of failures in writes?Google’s Spanner is a relational database with 99.999% availability which is roughly 5 mins a year. Spanner is a distributed system and…May 19, 2020May 19, 2020
Jaana DoganThings I Wished More Developers Knew About DatabasesA large majority of computer systems have some state and are likely to depend on a storage system. My knowledge on databases accumulated…Apr 21, 202032Apr 21, 202032
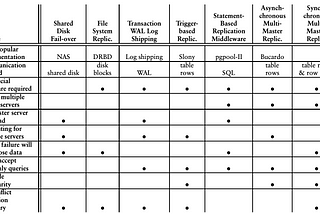
Jaana DoganinGoogle Cloud - CommunityPersistent Disks and ReplicationIf you are a cloud user, you probably have seen how unconventional storage options can get. This is even true for disks you access from…Oct 21, 20193Oct 21, 20193
Jaana DoganinObservability+Health, Availability, DebuggabilityAs we collect various observability signals from systems, it fosters a new conversation around the classification of the signals.May 9, 20191May 9, 20191